[Text Representation-4] Glove
본 포스팅은 고려대학교 강필성 교수님의 비정형데이터분석 강의를 보고 정리한 것임을 미리 밝힙니다.
Distributed Representation Models
- NNLM(2003) - Distributed Representation의 개념을 처음 도입한 Word Embedding계의 시조새
- Word2Vec(2013) - 주변 단어들의 정보를 활용해서 원하는 단어의 Embedding을 학습 (CBOW vs Skip-gram)
- Glove(2014) - 단어의 동시발생빈도를 고려해서 Embedding을 학습
- Fasttext(2017) - 학습 과정에서 보지 못한 단어(OOV)들과 형태소 변화에 대응할 수 있도록 Sub-word 개념을 도입
Glove
개요
Glove는 이전 Word2Vec 방법은 ‘The’, ‘a’와 같이 자주 등장할 수 있는 단어로 인해 연산량이 급격히 많아지며 학습에 방해가 될 수 있다는 문제점을 제기했다. 다시 말해 P(word: 함께 출현하는 단어 | the와 같은 자주 발생하는 단어)의 수치가 다른 P보다 높아 학의 불균형이 이뤄질 수 있다는 것이다. 따라서 이러한 문제에 대응하고자 본 방법에서는 단어 등장 빈도를 고려한 학습하는 방법을 제안하였다.
행렬 분해(Matrix factorization) 기반의 방식
Glove는 행렬 분해 기반의 방식을 이용하여 임베딩 벡터를 구성한다. 우선 동시등장행렬과 동시등장확률에 관하여 이해할 필요가 있다.
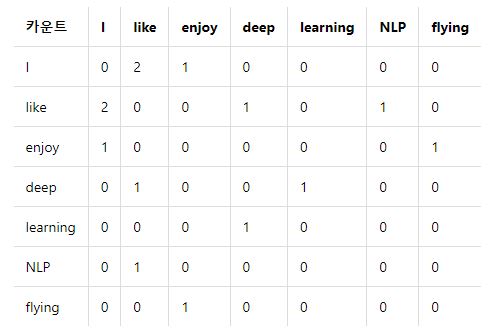
동시등장행렬 (co-occurrence matrix)
- i 단어의 윈도우 크기 내에서 k 단어가 등장한 횟수를 i행 k열에 기재한 행렬
-
전치해도 동일한 행렬
- 예시
- I like depp learning
- I like NLP
- I enjoy flying
동시등장확률 (co-occurrence Probability)
- 동시 등장 확률 $P(k | i)$ : 특정 단어 i가 등장했을 때, 어떤 단어 k가 등장한 횟수를 계산한 조건부 확률
- 동시 등장 행렬에서 i(중심단어)의 행의 모든 값을 더한 값을 분모, i행 k(주변단어)열의 값을 분자로 한 값
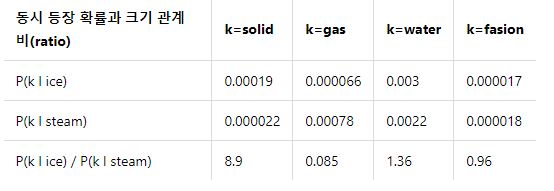
- ice가 등장했을 때, solid가 등장할 확률 = 0.00019
- steam이 등장했을 때, solid가 등장할 확률 = 0.000022
- steam이 등장했을 때, solid가 등장할 확률이 ice가 등장했을 때 solid가 등장할 확률보다 8.9배 큼
- 어떤 단어 k가 ice와는 관계가 있지만 steam과는 관계가 없다면(예: solid) $\frac{P_{ik}}{P_{jk}}$는 큰 값을 가져야 함
- 어던 단어 k가 steam와는 관계가 있지만 ice는 관계가 없다면(예: gas) $\frac{P_{ik}}{P_{jk}}$는 작은 값을 가져야 함
- 어던 단어 k가 ice/steam과 모두 관계가 있거나(예:water), 모두 관계가 없다면(예: fashion) $\frac{P_{ik}}{P_{jk}}$는 1에 가까운 값을 가져야 함
Formulation
- $X \in \mathbb{R^{V \times V}}$ : 동시발생행렬 (V x V)
- $X_{ij}$ : i번째, j번째 단어가 동시에 등장할 빈도
- $X_i = \sum_{k}^{V} X_{ik}$ : 동시발생행렬에서 i행의 값을 모두 더한 값 (전체 corpus에서 발생 횟수)
- $P_{ij} = P(j | i) = \frac{X_{ij}}{X_i}$ : i가 등장 했을 때, j와 함게 등장할 횟수
- $w_i \in \mathbb{R^d}$ : 중심 단어 i의 임베딩 벡터
- $\tilde{w_{k}}$ : 주변 단어 k의 임베딩 벡터
임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서의 동시발생확률이 되도록 만드는 것
- 세 단어 사이의 관계를 함수 F를 통해 정의
임베딩을 입력으로 받아 아래와 같이 관계를 보존해줄 수 있는 좋은 함수 F를 찾고자 하는 것
\[F(w_i, w_j, \tilde{w_k}) = \frac{P_{ik}}{P_{jk}} = \frac{P(solid | ice)}{P(solid | steam)}\]
- 두 단어 $w_i$와 $w_j$의 관계를 차이(subtraction)으로 표현
특정 단어 기준, 단어 간 차이를 임베딩 차이로 보자
\[F(w_i - w_j, \tilde{w_k}) = \frac{P_{ik}}{P_{jk}}\]
- $\tilde{w_{k}}$와 $w_i / w_j$의 관계를 표현하기 위해 내적 사용
단어 간 차이 임베딩과의 내적을 구하자 (스칼라 값 출력)
\[F((w_i - w_j)^T \tilde{w_k}) = \frac{P_{ik}}{P_{jk}}\]
Loss function
Homomorphism 의하여 아래와 같이 식을 구할 수 있으며, 이는 지수함수의 성질에 따라 다음 식들을 정의할 수 있다.
\[F(a + b) = F(a)F(b)\] \[exp(w_i^T\tilde{w_k} - w_j^T\tilde{w_k}) = \frac{exp(w_i^T\tilde{w_k})}{exp(w_j^T\tilde{w_k})}\] \[exp(w_i^T\tilde{w_k}) = P_{ik} = \frac{X_{ik}}{X_i}\]양변에 로그를 취하면,
\[w_i^T\tilde{w_k} = log(\frac{X_{ik}}{X_i}) = logX_{ik} - logX_i\]여기서 $log{X_i}$를 편향 $b_i$로 대체, 같은 이유로 $\tilde{w_k}$도 편향 $\tilde{b_i}$로 대체한다. 그러면 아래와 같이 손실함수를 정의할 수 있다.
\[L = \sum_{m,n=1}^{V} (w_i^T\tilde{w_j} + b_i + \tilde{b_j} - logX_{ij})^2\]하지만 이 손실함수는 여전히 단어 출현 빈도로 인해 학습에 대한 불균형 문제를 아직 해결하지 못했다. $X_{ij}$의 값이 작으면 함수에 정보를 여전히 적게 주는 것이다. 따라서 가중치를 둠으로써 적게 출현되는 단어에 대해 높은 가중치를 주는 새로운 수식 $f(X_{ij})$을 도입한다.
\[L = \sum_{i,j=1}^{V} f(X_{ij}) (w_i^T\tilde{w_j} + b_i + \tilde{b_j} - logX_{ij})^2\]Glove에 도입되는 $f(X_{ij})$의 식은 다음과 같이 정의된다.
- $f(x) = min(1, (\frac{x}{x_{max}})^\frac{3}{4})$
$X_{ij}$의 값이 작으면 상대적으로 함수의 값은 작도록 하고, 값이 크면 함수의 값은 상대적으로 크도록 한다.

댓글남기기